正弦计算比余弦慢几个数量级 |
您所在的位置:网站首页 › python 计算量比 › 正弦计算比余弦慢几个数量级 |
正弦计算比余弦慢几个数量级
|
回答问题
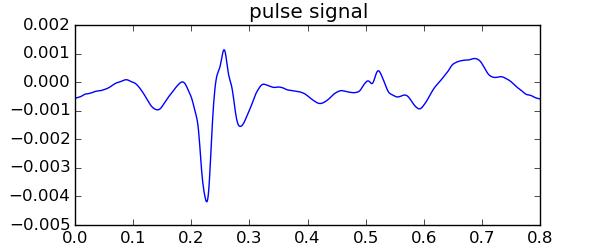
zoz100003 tl;博士 对于同一个numpy数组,计算np.cos需要 3.2 秒,而np.sin在 Linux Mint 上运行 548 秒_(九分钟)_。 有关完整代码,请参阅这个 repo。 我有一个脉冲信号(见下图),我需要将其调制到 HF 载波上,模拟激光多普勒振动计。因此,信号及其时基需要重新采样以匹配载波更高的采样率。
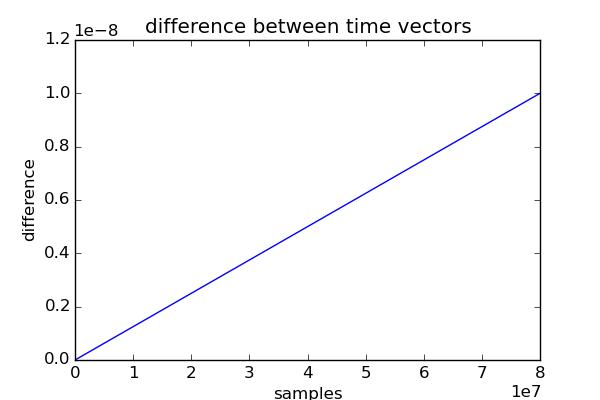
在接下来的解调过程中,需要同相载波cos(omega * t)和相移载波sin(omega * t)。奇怪的是,评估这些函数的时间很大程度上取决于计算时间向量的方式。 时间向量t1直接使用np.linspace计算,t2使用scipy.signal.resample](https://github.com/scipy/scipy/blob/v0.17.0/scipy/signal/signaltools.py#L1754)中实现的[方法。 pulse = np.load('data/pulse.npy') # 768 samples pulse_samples = len(pulse) pulse_samplerate = 960 # 960 Hz pulse_duration = pulse_samples / pulse_samplerate # here: 0.8 s pulse_time = np.linspace(0, pulse_duration, pulse_samples, endpoint=False) carrier_freq = 40e6 # 40 MHz carrier_samplerate = 100e6 # 100 MHz carrier_samples = pulse_duration * carrier_samplerate # 80 million t1 = np.linspace(0, pulse_duration, carrier_samples) # method used in scipy.signal.resample # https://github.com/scipy/scipy/blob/v0.17.0/scipy/signal/signaltools.py#L1754 t2 = np.arange(0, carrier_samples) * (pulse_time[1] - pulse_time[0]) \ * pulse_samples / float(carrier_samples) + pulse_time[0]如下图所示,时间向量并不相同。在 8000 万个样本时,差异t1 - t2达到1e-8。
在我的机器上计算t1的同相和移位载波需要 3.2 秒。 然而,对于t2,计算偏移的载波需要 540 秒。九分钟。对于几乎相同的 8000 万个值。 omega_t1 = 2 * np.pi * carrier_frequency * t1 np.cos(omega_t1) # 3.2 seconds np.sin(omega_t1) # 3.3 seconds omega_t2 = 2 * np.pi * carrier_frequency * t2 np.cos(omega_t2) # 3.2 seconds np.sin(omega_t2) # 9 minutes我可以在运行 Linux Mint 17 的 32 位笔记本电脑和 64 位塔上重现此错误。然而,在我室友的 MacBook 上,“慢正弦”的计算时间与其他三个计算一样少。 我在 64 位 AMD 处理器上运行 Linux Mint 17.03,在 32 位 Intel 处理器上运行 Linux Mint 17.2。 Answers我认为 numpy 与此无关:我认为您在系统上的 C 数学库中遇到了性能错误,该错误会影响 pi 的大倍数附近的 sin。 (我在这里使用非常广泛的“错误”——据我所知,由于大浮点数的正弦定义不明确,“错误”实际上是库在处理极端情况时表现正确!) 在 linux 上,我得到: >>> %timeit -n 10000 math.sin(6e7*math.pi) 10000 loops, best of 3: 191 µs per loop >>> %timeit -n 10000 math.sin(6e7*math.pi+0.12) 10000 loops, best of 3: 428 ns per loop和Python 聊天室报告中的其他使用 Linux 的类型 10000 loops, best of 3: 49.4 µs per loop 10000 loops, best of 3: 206 ns per loop和 In [3]: %timeit -n 10000 math.sin(6e7*math.pi) 10000 loops, best of 3: 116 µs per loop In [4]: %timeit -n 10000 math.sin(6e7*math.pi+0.12) 10000 loops, best of 3: 428 ns per loop但一位 Mac 用户报告 In [3]: timeit -n 10000 math.sin(6e7*math.pi) 10000 loops, best of 3: 300 ns per loop In [4]: %timeit -n 10000 math.sin(6e7*math.pi+0.12) 10000 loops, best of 3: 361 ns per loop因为没有数量级的差异。作为一种解决方法,您可以先尝试使用 mod 2 pi: >>> new = np.sin(omega_t2[-1000:] % (2*np.pi)) >>> old = np.sin(omega_t2[-1000:]) >>> abs(new - old).max() 7.83773902468434e-09哪个具有更好的性能: >>> %timeit -n 1000 new = np.sin(omega_t2[-1000:] % (2*np.pi)) 1000 loops, best of 3: 63.8 µs per loop >>> %timeit -n 1000 old = np.sin(omega_t2[-1000:]) 1000 loops, best of 3: 6.82 ms per loop请注意,正如预期的那样,cos 也发生了类似的效果,只是发生了变化: >>> %timeit -n 1000 np.cos(6e7*np.pi + np.pi/2) 1000 loops, best of 3: 37.6 µs per loop >>> %timeit -n 1000 np.cos(6e7*np.pi + np.pi/2 + 0.12) 1000 loops, best of 3: 2.46 µs per loop |
【本文地址】
今日新闻 |
推荐新闻 |